Summary
I compared the results for several websites that convert HTML webpage articles into EPUB. None of the websites that I tested provided consistently good results. A couple did provide the consistency of never actually working at all.
Introduction
Previously, I explored several iOS apps to read the PDF articles that I download/save. Unhappy with some of the formatting problems that come from saving HTML pages as PDFs, I decided to explore saving HTML pages as EPUB instead. There are several ways to do this: use a website converter, use a browser extension or use desktop computer software.
In this post I compare the results from several website converters. As I discussed in the previous blog post referenced above, I retrieve articles (and books) from multiple sources on several different devices. To convert website articles to EPUB using a website converter should be possible on any of the devices I use, though I only tested it on my desktop. Theoretically that means the process is flexible enough for my needs. Unfortunately, (spoiler alert!) based on my desktop testing I am not going to bother with testing the process any of my other devices.
Articles
To compare the output, I chose nine HTML articles, three each from three types of (somewhat arbitrary) categories: website articles, blog posts, and online journal articles. I wanted to the results for a variety of article characteristics, including things like images, code, quotes, references, comments, tables, etc. and different web page styles that would present a variety of formatting challenges.
Website articles
-
- Web APIs for non-programmers by Noah Veltman on School of Data
- XMLHttpRequest and AJAX for PHP programmers by James Kassemi on phpbuilder
- Why Tech’s Best Minds Are Very Worried About the Internet of Things by Klint Finley on Wired
Blog posts
-
- White Librarianship in Blackface: Diversity Initiatives in LIS by April Hathcock on In the Library with the Lead Pipe (Note: This site self-identifies a Journal, but the formatting is more blog-like than journal-like, hence its inclusion in this section.)
- Critical IoT Reading List – Summaries by Libby Miller at PlanB
- Dada Data and the Internet of Paternalistic Things by Sara M. Watson on The Message (Medium)
Journal articles
-
- Broken-World Vocabularies by Daniel Lovins and Diane Hillmann on D-Lib Magazine
- Recommendations for the application of Schema.org to aggregated Cultural Heritage metadata to increase relevance and visibility to search engines: the case of Europeana by Richard Wallis, Antoine Isaac, Valentine Charles, and Hugo Manguinhas on Code4Lib Journal
- Monuments of cyberspace: Designing the Internet beyond the network framework by Paris Chrysos on First Monday
Website Converters
A web search turned up 10 websites that claimed to convert HTML into EPUB. Five of them I didn’t use:
-
- Epubor Online eBook Converter — The small print on this website says that it will convert HTML, but I couldn’t enter a URL and it would not accept an uploaded HTML file.
- Zamzar — This site requires an email address, so I moved on without even trying it.
- 2epub — This site seems to be defunct.
- EPUB bud — This site requires an account, so I moved on without trying it.
- CloudConvert — Even though HTML to EPUB is listed on the site, it would only allow me to convert to PDF.
The other five websites I found all output at least one result, even if it was meaningless:
Comparison Results
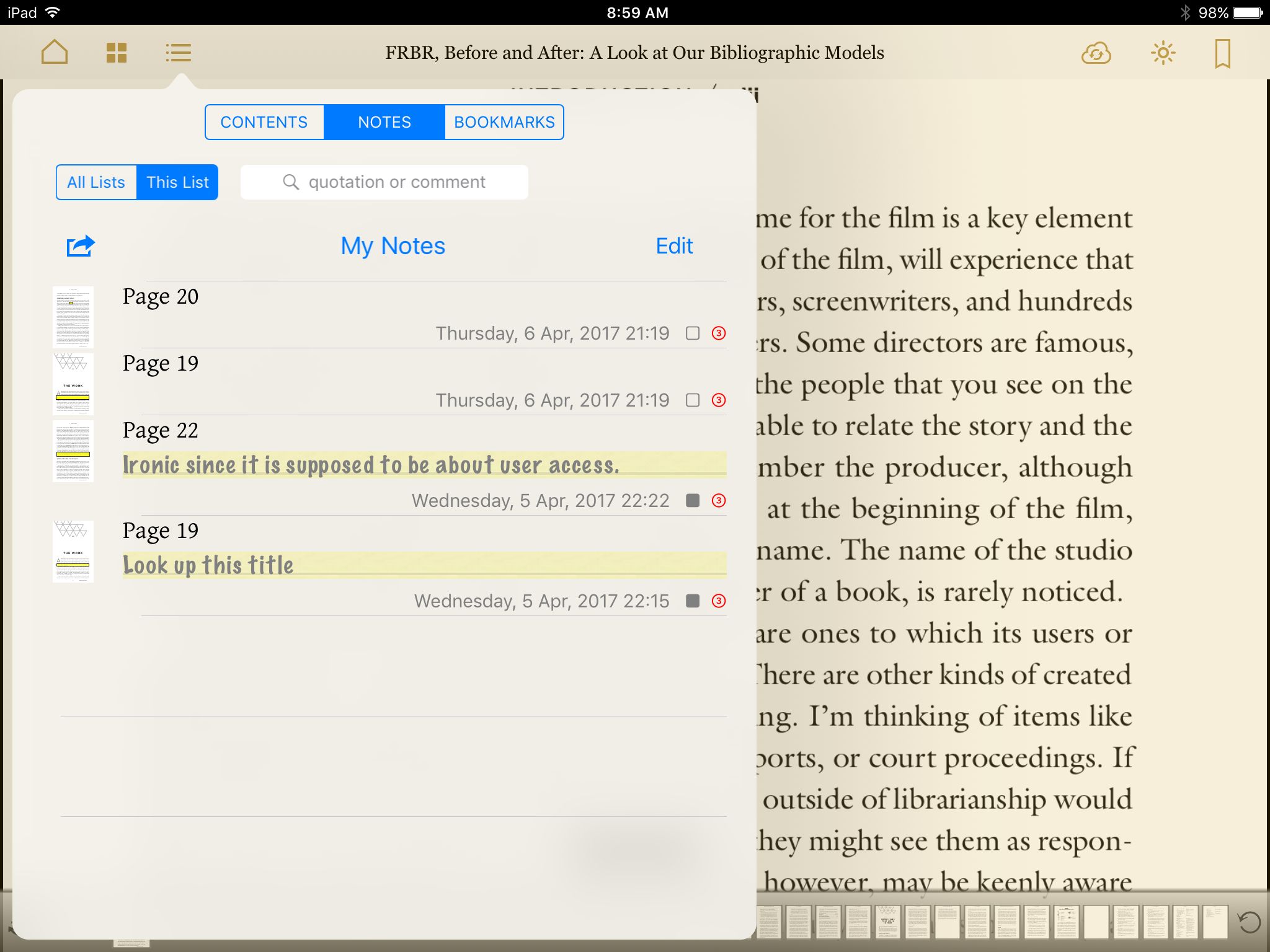
Using a Firefox extension (EPUBReader), I was able to open the EPUB files before I downloaded them to Dropbox. My initial impression of the output was not encouraging. However, since I was not planning to read them on my desktop but in an e-reader app on my iPad, I decided to withhold judgement until I had done a more detailed comparison of the files using the e-readers. I compared the resulting EPUB files in three e-readers on my iPad mini: KyBook 2, MapleRead SE, and ShuBook 2M.
I entered the URLs for nine articles into five website converters. In-ePub output a file for five of the nine articles. Online Converter and Online-Convert each output a file for eight of the nine articles. Go4Convert output a file for only one article. Convertio output a file for every single article; unfortunately, every single one of those files was empty.
None of the websites converted all of my test articles. Convertio failed the most often, with exactly zero successful conversions (also ironically making it the most consistent of the five). It simply created empty EPUB files. Online Converter and Online-Convert succeeded the most often with 8 articles each.
The simplest webpages turned into the best-looking EPUB files. But that is not saying much since the simplest webpages also produce the best PDFs. My problem is not the simple pages but the complicated ones. The EPUB converters did not (or could not?) really do any cleanup on the webpages. They did not seem to have any way to determine what on the page was relevant and what was not. Header, footer, and sidebar information often ended up being included in the EPUB file sometimes with and sometimes without the CSS that formatted it on the original webpage. This is perhaps an inherent weakness in trying to convert automatically from one format to another.
Within those basic parameters, there was some variety in the formatting applied by the converters. Online-Convert seemed to keep the closest appearance to the original webpages. This sometimes meant the articles looked the “best” in the EPUB readers but it also sometimes resulted in them looking the worst. MapleRead in particular had the most trouble with the formatting included by Online-Convert while ShuBook was the most forgiving (or possibly ignored the most webpage formatting?). The differently sourced EPUB files all looked the most similar in ShuBook.
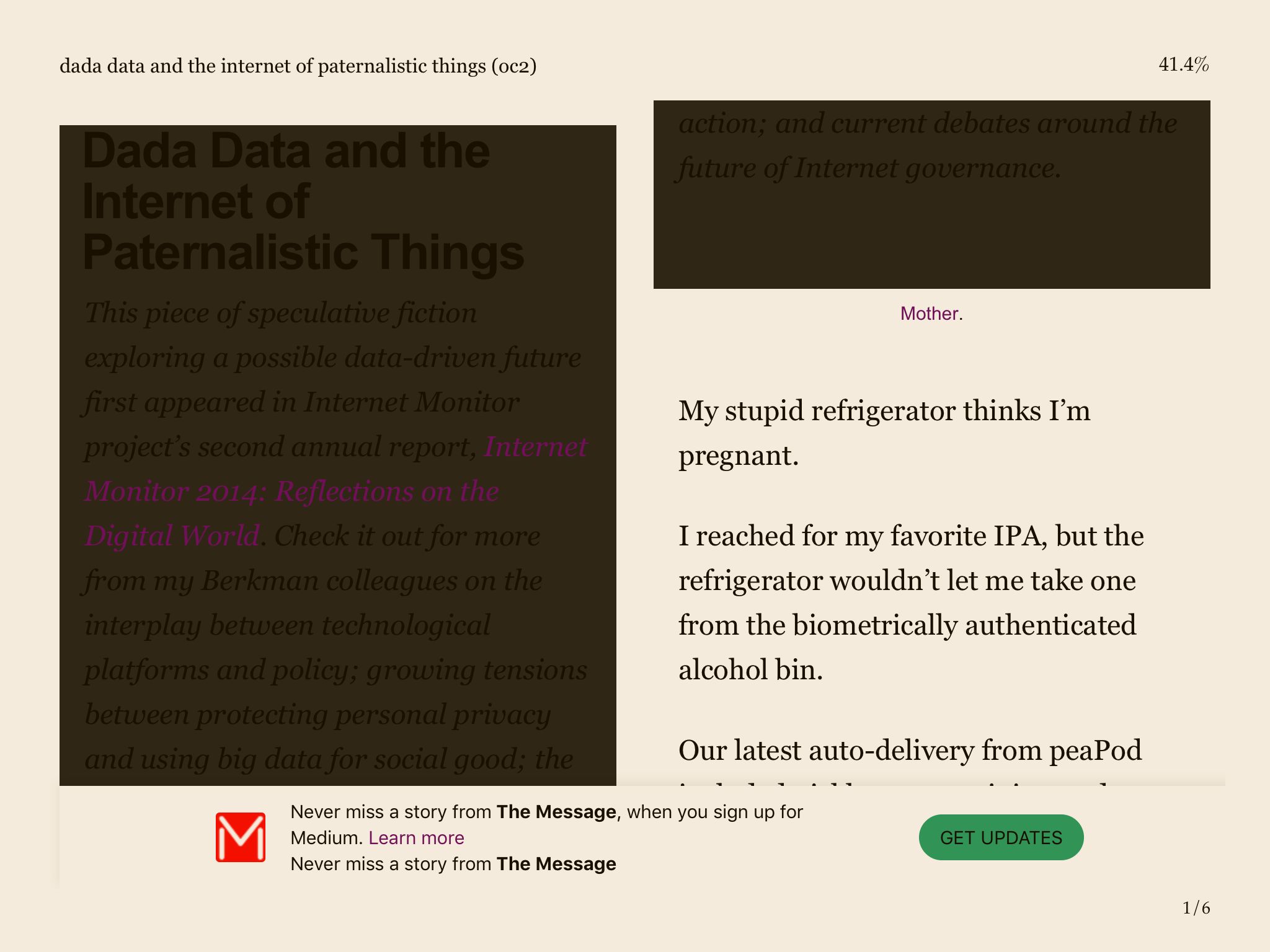


Images were the biggest problem. The default settings for the website EPUB converters do not seem to include the images. This is not a problem if the image is purely decorative, but when it is a diagram or figure illustrating something explained in the text, then it is certainly a deal-breaker to not include them. In-ePub and Online Converter did not include images in the converted files while Online-Convert did. The single article that Go4Convert converted did not include any images, so I have no conclusive data one way or the other for this converter.

Code generally did not cause any problems. It was easily discernible; set off from the text using a fixed-width font. Unfortunately, when the files output by Online-Convert had formatting conflicts with MapleRead, the code ran off the side of the page rather than wrapping around, making it impossible to see, let alone read. ShuBook code looked the best.

While about half of the webpages I converted allowed comments, only three articles actually had comments. Of those, only one converted EPUB file included the comments. The In the Library with a Lead Pipe article has over 70 comments which were included in the EPUB in all their glory. The Wired article includes comments but hides them by default and the phpbuilder article includes comments, but neither set of comments was included in the converted EPUB file.
Quotes and references generally did not cause any problems for any of the EPUB converters. While the exact formatting varied, both quotes and references were easy to distinguish from the rest of the text.
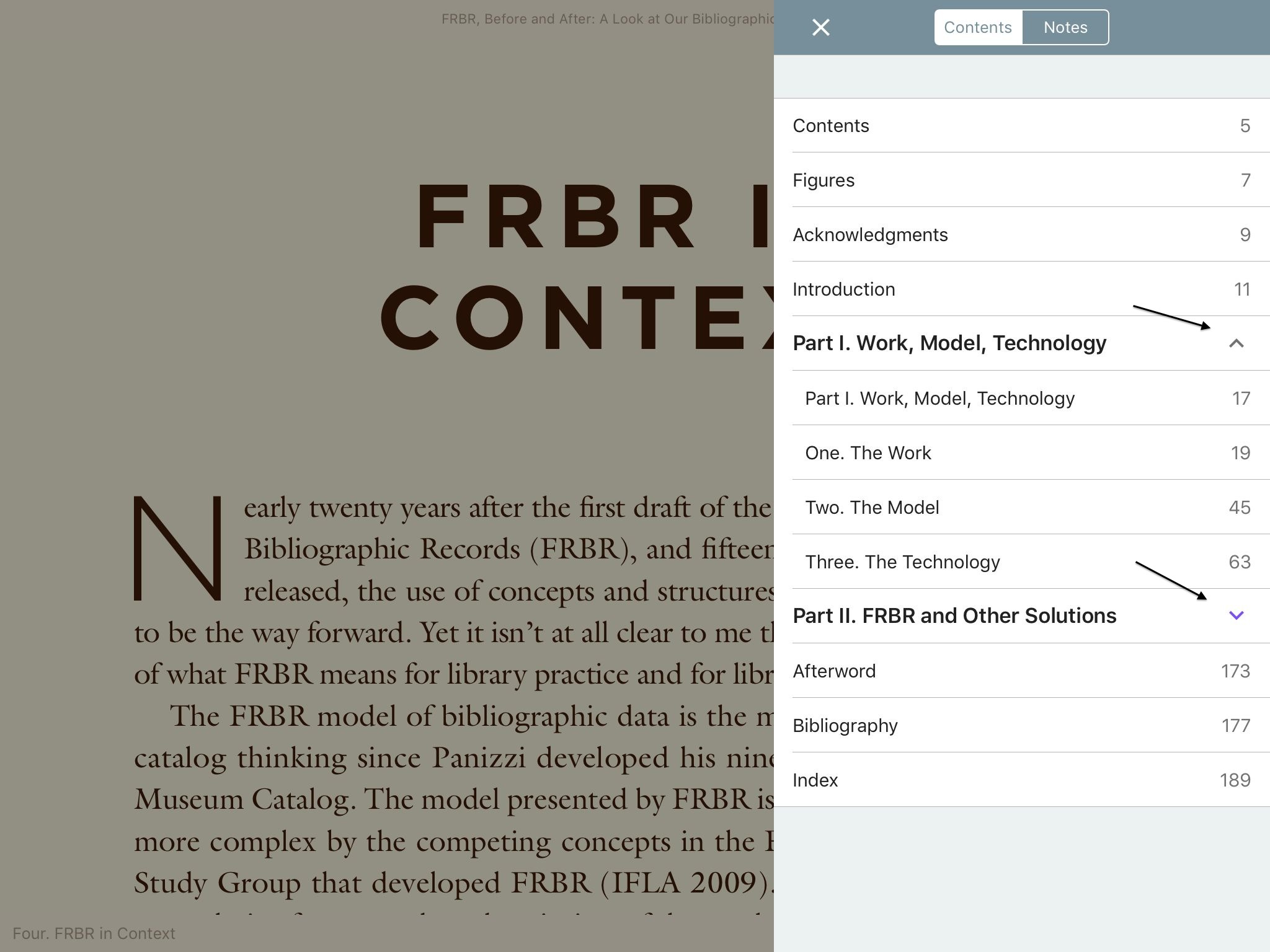
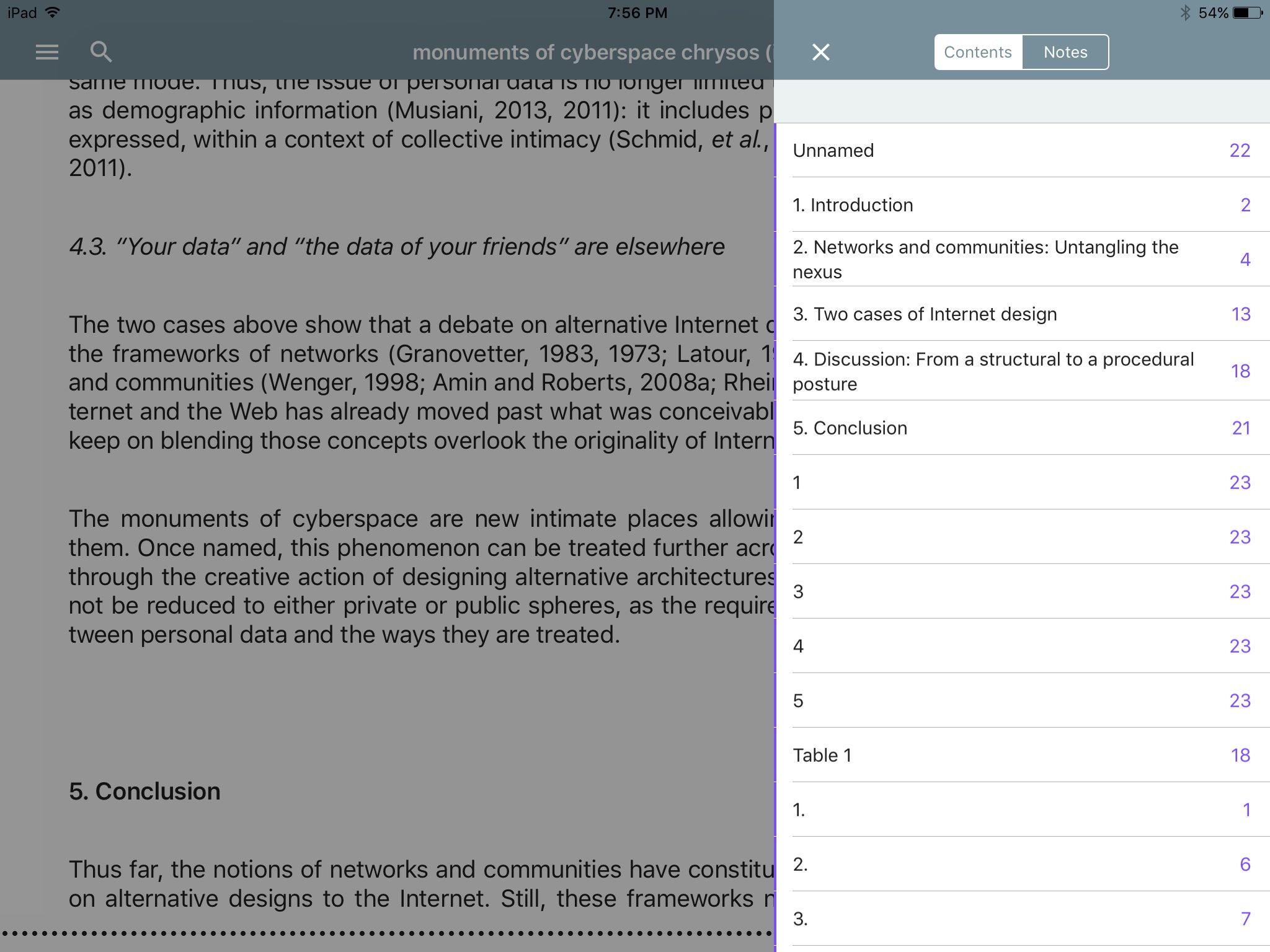
Finally, only one of the articles converted included a useful table of contents. For the rest of the articles, none of the converters produced useful output. In the e-readers, the information displayed varied from nothing to a random-looking list of entries unrelated to the actual sections of the articles. Even the EPUB file that included actual headings from the article also included a bunch of unrelated entries on the list. The output was consistent across converters; articles lacking a table of contents lacked it from all of the converters. The one article with a decent table of contents had the same list of entries from all converters. The apparent gibberish populating the table of contents for other articles was the exact same gibberish from each converter.
Conclusion
Comparing the EPUB files in my three e-readers confirmed my initial disappointment with the converted files. Converting HTML to EPUB has many of the same problems as converting HTML to PDF. There is such a diversity of ways that webpages are built that there is no one good way to catch them all. Website HTML to EPUB converters do not represent an improvement over converting to PDF for me and, in some cases, produced worse results. I am not going to use this method to convert HTML into EPUB.